クラウドではじめるデータマネジメント
アジリティとコスト削減に貢献する「データ仮想化」で
データ活用を加速化
アジリティとコスト削減に貢献する「データ仮想化」でデータ活用を加速化



本コンテンツは、当社が執筆している日経クロステック記事「実践DX、クラウドで始めるデータマネジメント 第10回「データ活用を加速する仮想化、データウエアハウスとは補完関係に」の内容を一部要約しつつ独自コンテンツを加えたものです。日経クロステック記事の全文はこちらをご覧ください。
目次
本記事では、データ仮想化の特徴や要件等について説明するとともに、データ仮想化の特に初期の活用において得られる、アジリティ向上や低コストといったメリットについて解説します。データウェアハウスとの違いを正しく把握することで、適材適所で使い分けることをお勧めします。
データ仮想化は探索型分析をスピードアップ − 特徴と要件
「データ仮想化」は、複数の物理的に分散したデータソースを仮想的に一つに統合し、アクセス可能にする技術やソリューションを指します。これは「データフェデレーション」とも呼ばれ、データ分析やビジネスインテリジェンス(BI)などの用途で利用されます。「データウェアハウス」とは相補的な関係にあるソリューションであり、両方を適材適所で使いこなすとデータ分析のアジリティを最大化できます。
探索型分析に有効な「データ仮想化」
データ分析のプロセスは大きく分けて「探索型分析」と「仮説検証型分析」の2つのステップから成ります。「探索型分析」では、社内外のデータソースを迅速にアドホックに確認し、新しいアイデアや仮説の抽出を行います。この段階はスピードと柔軟性が重要です。一方、本格的なデータ分析を行う「仮説検証型分析」では、より品質の高いデータが必要であり、ここではデータウェアハウスが重要な役割を果たします。このような違いがあり、分析の目的に応じてデータ仮想化とデータウェアハウスを使い分ける必要があります。
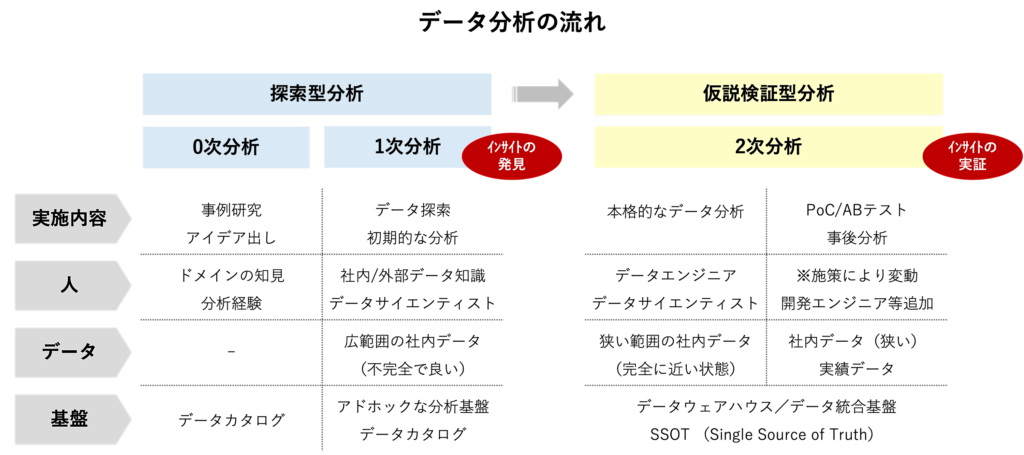
探索型分析の特徴と要件
探索型分析ではスピードが最も重要です。この段階では、散在するデータストアから迅速にデータを集め、デジタルトランスフォーメーション(DX)の企画、アイデアの創出、仮説の抽出に注力します。データの完全性や品質は、アイデアを出した後の実現性を確認する段階で重要になります。クリティカルな業務で利用するものではないため、分析基盤の可用性の要件も厳しくはありません。
探索型分析は、データを利用して新しいアイデアを生成し、実際のデータを確認しながら考えを修正し、具体化していくプロセスのため、事前に計画することが難しいという性質があります。分析者がどのデータを必要とするかを事前に特定することは困難であり、分析状況によって必要なデータが変化することもあります。そのため、探索型分析ではデータへの迅速なアクセスと高い柔軟性が求められます。
データ仮想化の効果と人材投資の重要性
データ仮想化はデータ活用のアジリティ向上とコスト削減に貢献
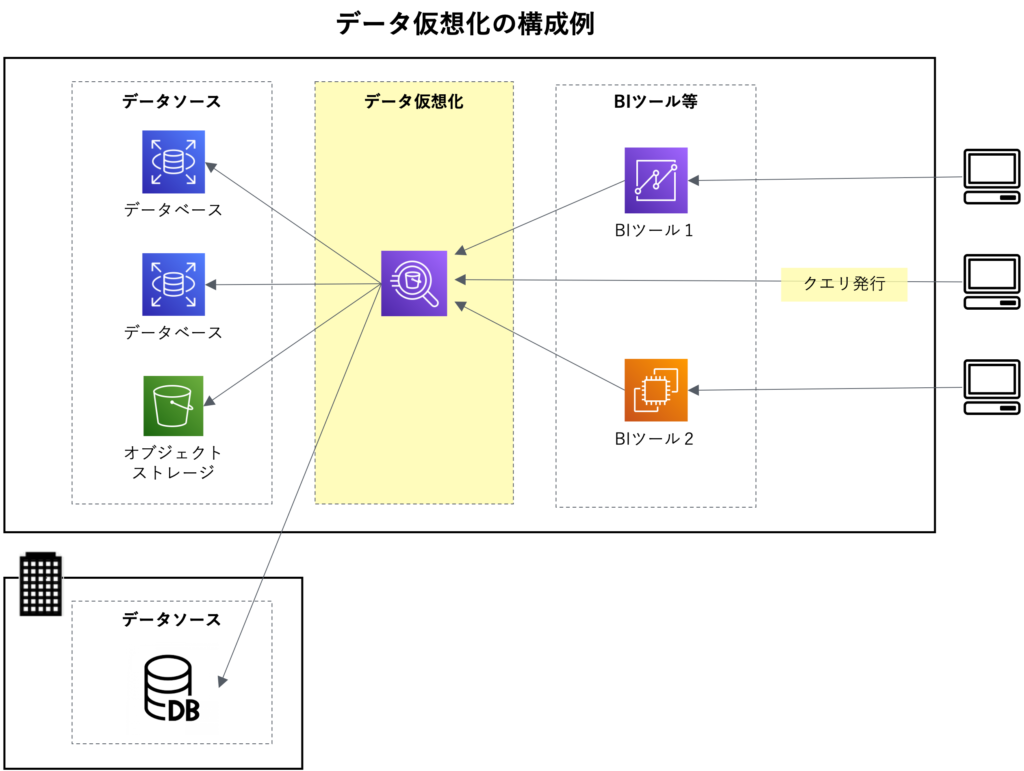
データ仮想化は、データ活用のアジリティ向上とコストの削減に大きく寄与します。アジリティが高いのは、図のように実データを持つデータ基盤に接続して利用する形態だからです。接続してデータにアクセスできるよう設定さえすれば、データ分析を開始できるので、導入と実装にかかる期間が短いという点が特徴です。低コストなのは、導入にかかる手間が少ないため、必要な人的リソースが少ないこと、また、データを分析基盤に収集する必要がないためです。クラウドサービスを利用することで、さらにコストパフォーマンスを高めることが可能です。図のように、利用者は直接クエリを実行したり、BIツールを通じてデータにアクセスすることが可能です。
データ活用投資に見合う成果を得るための「人」への投資
近年、国内の多くの企業がデータ活用の分野でデータウェアハウスに多くの予算を投じています。しかし、それに見合う成果を挙げていない事例が少なくありません。探索型分析の段階で質の高いインサイトを多く抽出できていないのも大きな要因と考えられます。
探索型分析に利用するデータ仮想化を低コストかつスピーディーに導入し、質の良いインサイトを出せるよう分析者やビジネスリーダーへの教育とトレーニングに投資することが重要です。これにより、データ駆動型の意思決定プロセスを強化し、企業のデータ活用能力全体を向上させることができます。
ここまで、データ仮想化のコンセプトとその特徴や利点について説明しました。
データ仮想化のためのデータマネジメント業務、クラウド上でのアーキテクチャ例については、日経クロステック記事で説明しています。ご興味がありましたらご覧ください。
クラウド環境のデータ仮想化サービスと商用データ仮想化製品の違い
クラウド環境では、ハイパースケーラのデータ仮想化(追加)サービスが広く利用されています。Amazon Web Services(AWS)では、Amazon Athena(Athena)というデータ仮想化(追加)サービスが提供されており、データレイクやリレーショナルデータベース(RDB)などの主要なデータソースに接続できます。Athenaの特徴は、異なるデータソースからのデータを結合して分析する機能を持ちながら、実際のデータをAthena自体に連係や格納する必要がない点です。
商用のデータ仮想化製品は、独自機能を持ち、強化を図っていますが、その分、料金が高めに設定されていることも多いです。これらの製品は、接続可能なデータソースの種類が豊富であり、クエリ実行結果のキャッシュなどによる性能向上の工夫をしています。データカタログ機能を内蔵している点も大きな特徴です。これらの機能は、探索型分析において高い親和性を持ち、効率的なデータ分析を実現します。
主要な商用製品には、米Denodo Technologiesの「Denodo Platform」や米TIBCO Softwareの「TIBCO」などが挙げられます。これらの製品は、独自機能を活用することで分析の初期段階における効率と精度を高めることが可能です。データ分析における初期投資に余裕がある場合には、これらの商用製品の採用を検討する価値があります。
次回のテーマは「データ品質管理」です。データ加工、データ連携と並び、コストがかかりやすい業務です。データ品質管理を低コスト化してデータ活用の価値を高めるアプローチについて説明します。






















