クラウドではじめるデータマネジメント
データ加工を劇的に変える3つのイノベーション
データ加工を劇的に変える3つのイノベーション



本コンテンツは、当社が執筆している日経クロステック記事「実践DX、クラウドで始めるデータマネジメント 第9回「データ加工に4つのトレンド、品質向上に不可欠な作業の全体像をつかむ」の内容を一部要約しつつ独自コンテンツを加えたものです。日経クロステック記事の全文はこちらをご覧ください。
目次
本記事では、データ活用のキモとなる「データ加工」について、その種類や処理方法などの基礎知識について説明します。また、データ活用の高まりとともに変化するニーズに対応した最新ツールやサービスの紹介をするともに、これらがデータ分析に大部分を占める「データ加工」を劇的に効率化できる可能性=DX高速化のポイント、について説明します。
データ活用の成功とスピードに影響する「データ加工の効率化」
データ加工は、前回の記事で解説したETLプロセスの「変換」の工程に該当します。データのフォーマット変更、クレンジング、名寄せなどを含みます。特に、データの整合性や一貫性に関する処理、例えば、クレンジングや名寄せは作業負荷が高くなりがちです。データ品質が低い場合、データ分析作業の大部分がデータ収集と加工に費やされることが珍しくありません。データ加工をいかに効率的に実行できるかがデータ活用のスピードと成功率に大きく影響します。
データ加工の種類と内容
| データ加工の種類 | 内容 |
|---|---|
| フォーマット変換 | データ利用するシステムでの処理に都合の良いデータ形式や単位に変換する。フォーマット変換にはCSV、JSONなどのファイルフォーマットの変換と、日時表現方式、大文字小文字・全角半角、氏名・住所の区切り方などのデータ型・表現形式の変換がある |
| クレンジング | データセット内にある、不正確、不完全なデータを検出し、修正または削除する処理。データクレンジングの目的は、データを正しい状態に修正し、データの信頼性を向上させること。データ分析の精度や処理結果に大きな影響を及ぼす |
| 名寄せ | データの重複を修正すること。データ間の同一性を判断しデータを統合する |
| データ補完 | データ内の欠損値を埋める処理。補完方法は、他のデータソースからの取得、計算結果の挿入などがある |
| データ正規化 | データの整合性を保ちやすいデータ構造にする手法。データに冗長性がなく1カ所で表現されるような構造にする。データベースでデータを利用する際に実行される。正規化することによって、データの更新、削除、挿入処理の効率がよく、データの整合性が崩れにくくなる |
| マスキング、匿名化 | 機密情報または個人を特定できる情報を保護するために不可逆なデータ加工を施す手法 |
| データ分割、データ統合 | 利用に適した単位に分割、統合する処理。日時やデータソースごとに分かれているファイルを1つに統合したり、機械学習用データを教師データと検証データに分割する加工処理などがある |
| マート作成 | レポート等の特定の利用目的に特化してデータウェアハウス上のテーブルを作成すること |
複雑化するデータ加工
データ加工においては、加工対象となるデータフォーマットの多様化が進み、複雑化しています。以前は定型化されたデータフォーマットである構造化データが大半を占めていましたが、近年では構造化されていないデータを加工することが多くなっています。
構造化されていないデータには、半構造化データと、非構造化データがあります。
構造化データ
明確に定義されたデータを「構造化データ」と呼びます。予め決められたフィールド名と形式、型・桁にしたがってデータが整理されており、定義に反するデータは存在しません。リレーショナルデータベースに格納された業務データが代表例です。
半構造化データ
一定の構造はあるものの、構造化データほどの明確さや厳密さはないデータを「半構造化データ」と言います。代表的なデータフォーマットには、JSON(JavaScript Object Notation)、Parquet(Apache Parquetの列指向データ記述方式)、GeoJSON(地理空間データ記述方式)、RDF(Resource Description Framework、メタデータ記述方式)などがあります。データ分析ではアプリケーションやシステムで作成される各種ログを頻繁に利用します。これも半構造化データです。データ加工対象の多くを占めるようになってきました。
非構造化データ
「半構造化データ」は決まった構造のないデータのことです。SNSなどのテキストや、音声、画像、映像などがこれにあたります。非構造化データの加工にはAIが効果的です。
本記事では、構造化データと半構造化データのデータ加工を取り上げます。非構造化データのデータ加工に関するAIサービスや手法については、別の機会で説明します。
データ加工を劇的に変える3つのイノベーション
データ活用ニーズが高まるにつれ、一般のビジネスパーソンもデータの活用・加工に関わるようになってきました。また、対象データの種類が増え、実装頻度も高くなってきました。クラウドではこれまでなかった種類のサービスが登場し、データ加工の効率を劇的に高める可能性があります。
非エンジニアのデータ加工実務を可能にするノーコード・ローコードツール
画面操作だけでデータ加工を可能にする「ノーコード・ローコード型ツール」が徐々に普及しています。ノーコード・ローコードツールの普及は、データ加工を劇的に変える2つの意義があります。
これまでは主にエンジニアがデータ加工を行っていましたが、これらのコード記述やプログラミング不要の直感的ツールのおかげで、技術的な専門知識がないユーザーでもデータ加工が行えるようになっています。
「コードの記述量が減る」ということは、データ加工処理を実装する作業の生産性を高められる「可能性」があるということです。「可能性」という表現にした理由は、生産性向上の効果は、ツールやサービスの得意なデータ加工の種類かどうかで変わるからです。ツールの特性をしっかり把握したうえで選択する必要があります。
もう1つの意義は、「業務部門だけでできることが増える」ということです。つまり、変革を広範囲かつスピーディーに進められるかどうかのカギは、デジタルトランスフォーメーション(DX)を主導する業務部門が握っているということ。非エンジニアでも利用できるツールやサービスの開発はここ数年で大きく進みつつあります。業務部門のビジネスパーソンがデータ収集、データ加工、データ活用の手段を持ち、自力でデータ加工を実行することで、DXを加速することができます。
AIを活用したデータ加工で、可能な範囲から自動化
AI(人工知能)を活用したデータ加工サービスが発展しはじめており、品質に問題があるデータに対して自動的に改善案を提示できるようになっています。
もちろん、ツールが提案するデータ加工案を採用するかどうかの判断は人が関わる必要があるため、完全な自動化は難しいですが、自動実行できるルールはそのまま適用し、それ以外は人間が関わる形で利用することが可能です。自動化に対応しているするサービスでは、項目名、データ型、タグなど、不足しているメタデータやラベルの補完も行えるようになっています。
特定領域で専門性を発揮する「特化型SaaS」の活用で精度と効率を向上
「顧客情報を名寄せするSaaS」のように、特定のデータ領域や目的に特化したSaaSも登場しています。一般的な用途では、顧客情報や企業情報などのデータセットに対する名寄せやクレンジングをサポートするものが代表例です。
特化型SaaSは、専門分野のデータに特化した自動加工において高い精度を誇ります。自社で扱うデータセットがこれらのサービスが対応するデータ領域と一致する場合、特化型SaaSはデータ加工における強力な選択肢となり得ます。このようなサービスは、専門知識を要するデータ領域において加工作業の精度と効率を大幅に向上させることが期待できます。
データ加工の全体像と4つのステップ
データ処理は「前処理」、「統合」、「正規化」、「マート作成」のステップに分けて順番に実行します。このデータ加工の流れを「データパイプライン」と呼ぶことがあり、データを加工、連携しながら流れる様子を表しています。
ここで重要なポイントは、データ処理を一度行い、それを複数のデータ活用システムで再利用するためには、重複する処理を避けて一元化することです。データレイクを活用することで、このようなアーキテクチャーを実現しやすくなります。また、データ加工のステップによって適したツールが異なる場合があるので、ツールを適切に組み合わせることも重要です。
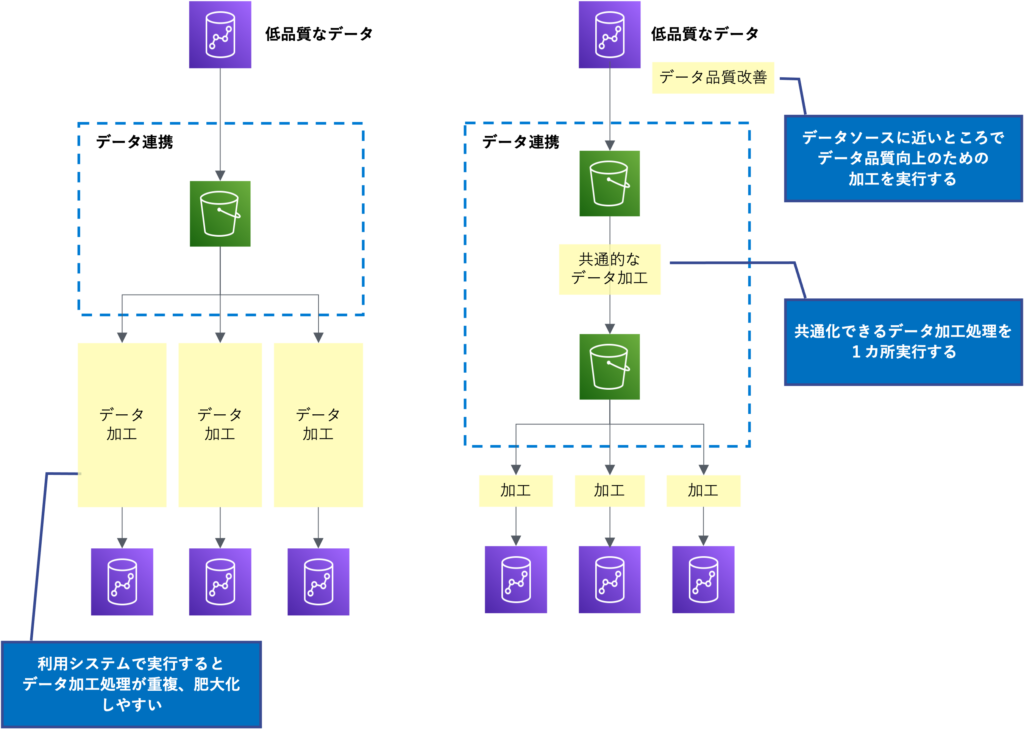
次に、一般的なデータパイプラインを例に、各ステップでどのようなデータ処理をするのかについて説明します。
前処理 ー データの欠損値や異常値を処理
このステップでは、収集された生データに対して初期的な加工を行います。具体的には、データのフォーマットを変更したり、欠けている部分を補ったり、異常値を取り除いたりする作業を含みます。目的は、最低限のデータ品質を保ちながら、後続するデータ加工ステップを実行しやすくすること。前処理の質が最終的なデータ分析の正確性や結果に影響を及ぼすため、重要な作業です。
統合 ー データを有効・有益に利用するための整理・統合
このステップでは、前処理を経たデータに対して、より高度なクレンジング、データの補完、および、名寄せを行います。目的はデータの整合性と一貫性を保つための変更や統合です。顧客の属性や行動履歴などのデータには、同一の情報が複数の表現形式で重複して存在しているため、「名寄せ」を行い、同一の情報として一元的に整理・統合することで、マーケティングや営業、コンタクトセンターなどでの利用価値を高めます。
さらに、セキュリティ上の必要に応じて、個人情報の匿名化やマスキングを行います。これにより、個人情報へのアクセス権限がないメンバーでもデータ分析を行うことができるため、データ活用の範囲が広がります。統合されたデータは社内で共通のデータセットとして再利用されます。
このステップは、データ加工ステップの中で最も複雑で実装負担が大きい部分です。他のデータセットとの照合や複雑な処理が必要な場合は、データレイクではなくリレーショナルデータベースなどを活用する方が、コストと効率の面で有利になることがあります。
正規化 ー データの整合性を保つためのデータ設計
データの正規化は、データの更新、削除、挿入の処理をより効率的に行えるようにし、データの整合性を保つために重要なステップです。特に、リレーショナルデータベース(RDB)にデータを格納する際には、正規化が不可欠です。正規化のプロセスでは、RDBが得意とする他のデータセットとの照合や結合処理が多く行われ、また、RDB固有のキー構造などの設定も必要になります。これらの理由から、正規化は主にRDB上で実施されることが一般的です。これにより、データの一貫性を保ちつつ、効率的なデータ管理が可能になります。
マート作成 ー 利用目的に個別最適したデータセットの作成
データウェアハウスを使用する場合、データを正規化した後にデータマートの作成を行います。データマートは特定の使用目的に特化したデータ加工の一種です。このアプローチでは、予め集計や分析が行われたデータを保持しておくことで、データの参照速度が高速化されるというメリットがあります。
本記事内で説明した各種データ加工は、データプレパレーションツールと呼ばれるツールやサービスで自動化します。その際に考慮するポイントや注意点、前出の特化型SaaSの主なサービスなどは日経クロステック記事で説明していますので、ご興味がありましたらご覧ください。
次回のテーマは「データ仮想化」です。データ分析の前半戦を高速化するために、データ仮想化がいかに役立つかについて説明します。






















