クラウドではじめるデータマネジメント
信頼性とアジリティを両立する
データベース信頼性エンジニアリング(DBRE)
信頼性とアジリティを両立するデータベース信頼性エンジニアリング(DBRE)



本コンテンツは、当社が執筆している日経クロステック記事「実践DX、クラウドで始めるデータマネジメント 第21回「変化と安定を両立、データ基盤運用に求められるデータベース信頼性エンジニアリング」の内容を一部要約しつつ独自コンテンツを加えたものです。日経クロステック記事の全文はこちらをご覧ください。
目次
データ活用のアジリティを上げるデータ基盤運用の実践的な取り組みが「データベース信頼性エンジニアリング(DBRE)」です。DBREはデータ基盤の信頼性を保ちながらアジリティを上げて変革に寄与する運用を、エンジニアリングによって実現しようとするものです。この記事ではDBREについて従来型のデータ基盤運用と対比しながらデータ基盤運用を変革する意義について解説します。
データベース信頼性エンジニアリング(DBRE)が求められる背景
デジタルトランスフォーメーション(DX)では、システムの信頼性と、迅速な変更やイノベーションの促進の両立が求められます。オンプレミスの基幹システムを中心に安定性を最優先した従来の運用スタイルがフィットしなくなってきました。
DXと運用スタイルの変革
DXの推進において、システムを頻繁に更新・改善します。アプリケーション開発の世界ではCI/CD、生成AIを活用した迅速な開発・リリースが進展しているのに対して、安定性を最優先に考える従来のデータ基盤運用がアジリティの要求に応えられていない場面が往々にしてあります。DXを成功させるためには、開発スタイルだけでなく、運用スタイルも根本から見直す必要があります。
社会的背景と運用の労働生産性改善
労働人口の減少やエンジニアの採用が困難という社会的背景は、運用スタイルを見直す大きな動機となっています。従来のデータ基盤運用では障害対応や日常オペレーションに多くのリソースを割いており、これらは付加価値を生まないコストセンターと見なされがちでした。しかし、現代のビジネス環境では、運用もまたイノベーションに貢献する重要な組織部門であるべきで、労働生産性を高めて前向きな貢献をすることが求められます。
データベース信頼性エンジニアリング(DBRE)とは
データベース信頼性エンジニアリング(DBRE)はSREのDB版
「データベース信頼性エンジニアリング(DBRE)」は、「サイト信頼性エンジニアリング(SRE)」の原則をデータベース管理に適用したものです。SREは、Googleによって開発された「サービスの信頼性を確保しつつ、イノベーションの速度を保つための戦略的アプローチ」であり、安定性と運用コストのバランスを取りながら、システムの持続的な改善を追求します。ソフトウェアエンジニアリングの手法を運用業務に取り入れることによって、プロアクティブな自動化と改善を通じて品質を高めることを目指しています。
DBREと従来型のデータ基盤運用との比較
| 従来型のデータ基盤運用 | DBRE (Database Reliability Engineering) | |
|---|---|---|
| データ基盤の変化 | 数年に一度再構築。それ以外の期間はできるだけ変更しなくて済むよう管理 | 短期的に部分設計・変更を繰り返して成長させていく |
| 目標 | トラブルの最小化 | 信頼性目標の達成とシステム改善の両立 |
| 業務内容 | 作業メニューベースでの固定的な運用オペレーション | 信頼性に紐づく業務を動的に実行する。自動化と改善に工数の一定割合を割く |
| 保守作業 | パッチ適用、領域管理などを手作業で実施 | オペレーションの多くが自動化されて不要になっている |
| 開発チームとの関係 | 縦割りで障害対応などの際に必要なコミュニケーションを取る | 協力関係。データモデル、クエリの品質をプロアクティブに改善する支援をしてトラブルを防止する |
DBREにおける信頼性とは
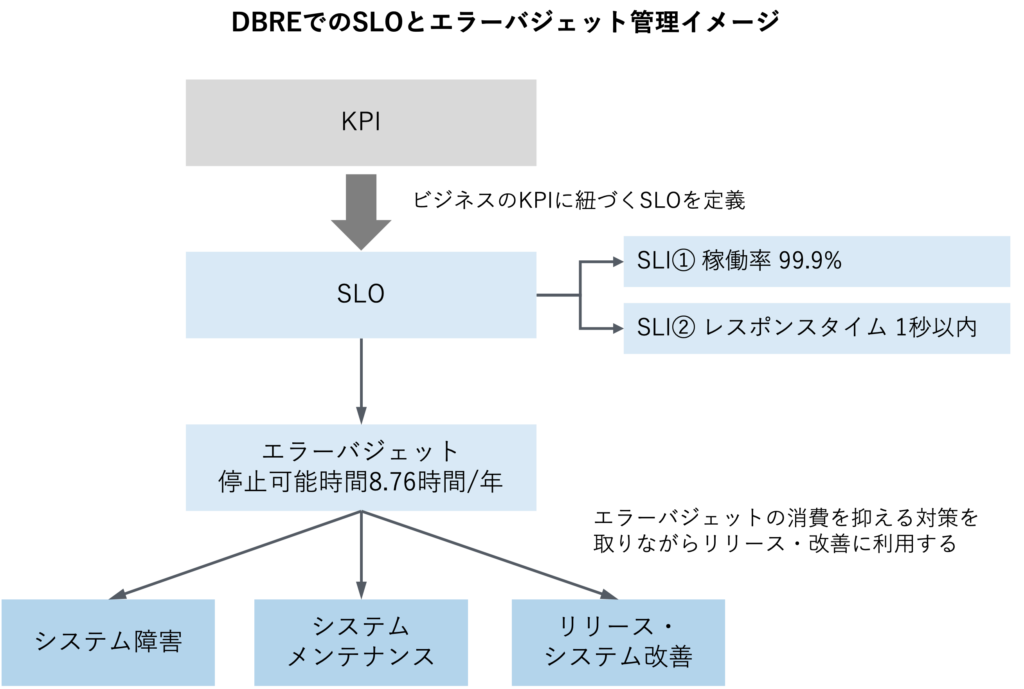
データベース信頼性エンジニアリング(DBRE)の実践では、サービスレベル目標(SLO)の設定が重要です。SLOは、システムやサービスが達成すべき目標を定めるものです。SLOを達成するためには、複数のサービスレベル指標(SLI)を設定し、これらがどの程度達成されているかを定期的に評価します。
SLIとSLOの例
SLIの典型的な例としては、システムの稼働率があります。稼働率は、システムが正常に稼働している時間の割合を意味し、特定の期間内で計算されます。たとえば、99.9%の稼働率は年間で約8.76時間までのダウンタイムを許容することを意味し、99.99%の稼働率ではダウンタイムを年間52.56分以下に抑える必要があります。
エラーバジェット
DBREとSREでは「エラーバジェット」という特徴的な概念を用います。エラーバジェットは、ある期間内に許容される最大のダウンタイム量です。これにはシステム障害だけでなく、計画的なメンテナンスやアップデートによる停止時間も含まれます。このバジェット内でデータ基盤の改善やアップデートを積極的に計画します。ダウンタイムをとにかく最小限に抑えることを目標にした従来の運用スタイルとは決定的に異なる点です。DBREを実践するデータベース信頼性エンジニアは、安定性と同時に、システムの前向きな改善を目指します。
データ基盤とSLOの重要性
データ基盤はシステムのパフォーマンスや安定性に直接影響を及ぼすため、SLOの管理が特に重要です。稼働率のほかにレスポンスタイムやスループットも重要なSLI指標となります。これらの指標を総合的に管理し、システムのパフォーマンス目標を達成することが求められます。
ビジネス視点の重要性
SLOとSLIの設定には、ビジネス目標との整合性が必要です。ビジネスの重要業績指標(KPI)に基づいてシステムのパフォーマンス目標を設定することが理想的ですが、実際にはこのような連携が取れていない場合も少なくありません。SLIを設定する際には、コストとリスクのバランスを考慮し、サービスの品質とコスト効率の最適なバランスを見つけることが重要です。
データベース信頼性エンジニアリング(DBRE)による改善
業務の自動化と改善に工数を配分し、工数削減と品質向上を実現
運用の現場では、定常的な作業で工数が埋まってしまい、前向きな改善に取り組めないことがよくあります。運用担当者は一生懸命がんばっているのに、アジリティを伴わないために評価されないという不幸な運用現場を過去にたくさん見てきました。
そういった状況を打破するため、データベース信頼性エンジニアリング(DBRE)では運用業務の自動化に一定の工数を配分します。DXのためのデータ基盤は変化が大きいため、対策を講じないと運用工数が膨らんでいきます。正しく自動化すると工数を削減でき、人手による作業を排除することで品質も向上します。
主要な改善アクションは以下のとおりです。
モニタリング
異常の兆候を検出するために状況をモニタリングします。異常を迅速に通知して、インシデント対応を効率化します。
ポストモーテム
インシデントが発生した場合、その原因を分析し、教訓を得ることを「ポストモーテム」といいます。同様の問題の再発防止策を講じて、長期的な品質向上を図ります。
学習
DBREチームのスキル向上とノウハウの共有を通じて、最新の技術や手法をデータ基盤の運用に活用します。これにより、運用の効率化とデータ基盤の改善につながります。
開発チーム支援
データモデルやクエリの最適化に関するレビューやアドバイスを提供することで、開発プロセスにおける問題を予防し、全体的な開発生産性の向上を図ります。
データベース信頼性エンジニアに移行するには?
オペレーションを中心としたデータベースエンジニアが「DBREを担当するデータベース信頼性エンジニア」に移行するにはハードルがあります。最も難しいのはマインドセットの変化です。受動的にトラブルや課題に対応するスタイルから、能動的に改善や変更をしていくスタイルへの変革には困難が伴います。
スキルセットのギャップもあります。DBREは「エンジニアリング」のため、仕組みがあればオペレーターで実行できるものではなく、経験を積んだエンジニアの存在が必須です。行動変容や体制変更が必要になることが多いですが、移行できるとデータ活用のアジリティが上がるという効果を獲得できます。
当社では、難度の高いDBREへの移行を支援する「データベース信頼性エンジニアリング(DB運用)サービス」を提供していますので、まずはお気軽にご相談ください。
KPIを守るためのシステム的な対策やパブリッククラウドサービスを活用したDBREの基盤構成のやり方については、日経クロステック記事で説明しています。ご興味のある方はご覧いただければと思います。
17回に渡り解説させていただいた「クラウドではじめるデータマネジメント」も今回が最終回です。最後までお読みいただき、ありがとうございました。
データマネジメントやデータ活用の分野では、新たなノウハウや基盤が次々に登場し、目が離せません。引き続き記事や講演等を通じて情報発信していきますので、今後もご期待ください。






















