クラウドではじめるデータマネジメント
複雑なデータ基盤のガバナンスと個別最適化を
両立するデータメッシュ
複雑なデータ基盤のガバナンスと個別最適化を両立するデータメッシュ



本コンテンツは、当社が執筆している日経クロステック記事「実践DX、クラウドで始めるデータマネジメント 第19回「複雑化するデータ基盤のガバナンス、統制しつつ個別最適化するデータメッシュ」の内容を一部要約しつつ独自コンテンツを加えたものです。日経クロステック記事の全文はこちらをご覧ください。
目次
この記事では、データメッシュの特徴やメリット・デメリットなどの基礎情報について説明します。データメッシュとは、データ活用がある程度進んで複雑化した基盤構成になった際に直面する課題に対応する1つの解決策です。やや応用的なトピックになりますが、特に大企業や複雑な組織構造の企業では対処を要する可能性が高く、予備知識として持っておくと重宝します。データメッシュを実現するための業務内容やソリューションについても軽く触れます。
「データメッシュ」が必要なケースとは?
企業がデジタルトランスフォーメーション(DX)を進めていくと、複数のデータ基盤が生まれることがあります。これには様々な理由があります。例えば、ある特定の事業部では独自性が高いため、他の事業部とデータ基盤共有を避けるといったケースがあります。
新規事業では、既存事業の制約を受けず、より柔軟に運営するために新しいデータ基盤を構築するケースも見られます。企業の合併や買収が頻出する現在では、異なるデータ基盤を持つ事業や企業を統合した結果、複数のデータ基盤を持つこともあります。
セキュリティー要件もデータ基盤を分ける要件の1つです。例えば、極めて機密性の高いデータは、社内データセンターでのみ管理され、クラウドのデータ基盤とは分離されることがあります。さらに、EUの一般データ保護規則(GDPR)のような法規制に対応するために、地域ごとに異なるデータ基盤を設けて、地域内で個人情報を保持する場合があります。
複数のデータ基盤を保有することで、データガバナンス上の課題も発生します。分散したデータ基盤間では効率的なデータ共有が困難になりやすいからです。複数のデータ基盤間でデータの安全性を保つために、一貫したセキュリティー基準を維持する必要があります。
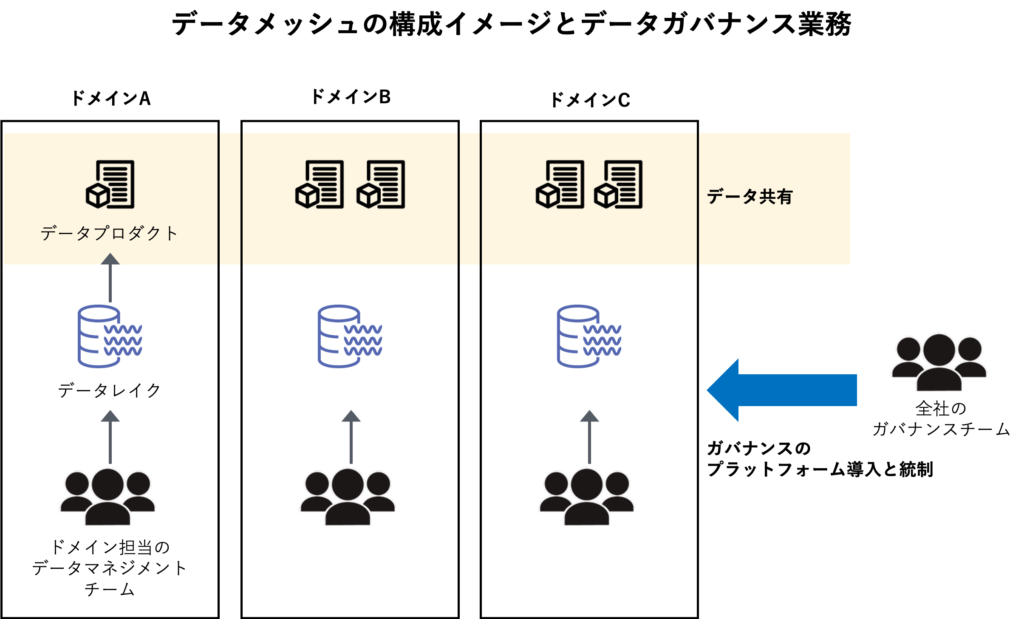
このような課題に対処するために、「データメッシュ」という分散型データアーキテクチャーが提案されています。データメッシュでは、業務や事業単位(ドメイン)に基づいて論理的なデータセットを定義し、それぞれのドメインに割り当てられたデータマネジメントチームがデータの管理を行います。
分散したデータ基盤で、ドメイン志向のデータ管理を実現する
データメッシュ
全社統率と分散管理を両立する「連邦型データマネジメント」
データメッシュは、ドメインごとに異なるデータマネジメントのアプローチを採用できるという自由度が高く、柔軟な性質から「連邦型」と称されます。セキュリティーなど、企業全体で守るべき基準は、中央のガバナンスチームが設定し、各ドメインのデータマネジメントチームがこれを実施します。
他のドメインに共有するデータを「データプロダクト」と言い、ドメインを管理するデータマネジメントチームが利用しやすい形で共有します。ドメイン内だけで保持すべきデータは共有せずに管理します。
データメッシュの大きな利点は、データ共有する仕組みを持ちながら、ビジネスドメインごとのニーズに応じて最適化できる点です。データの統合的な活用は重要ですが、事業部やチーム内の効率的な業務実行も同様に重要です。データメッシュは相反する要求を両立できる可能性のあるソリューションです。
データ統合に要する物理的な手間が小さい点もメリットです。独立した事業部やグループ企業間で単一のデータレイクに統合しようとすると、調整や移行コストが増大する可能性があります。
しかしながら、データメッシュにはデメリットもあります。分散型であるため、一か所に集められたデータを直接利用することが難しい点や、データを取得・利用する際には、データの物理的取得や仮想的統合を可能にするサービスが必要という点です。
また、各ドメインでデータマネジメントを行う負担が増加するという点もデメリットです。分散管理を効果的に行うためには、各ドメインで自己完結できるよう、データエンジニアやデータスチュワードなどの役割をそれぞれに設ける必要があります。
データメッシュを実現するための業務とソリューション
データメッシュは、論理的なデータ管理の新しいアプローチであり、抽象度が高い概念です。このアプローチでは、データガバナンスや共有の基準・ルールの設定などのデータマネジメント業務と、それらをシステム的に支えるソリューションの導入が不可欠です。特にクラウドテクノロジーに焦点を当てた考え方であり、これを実現するソリューションの多くがクラウドサービスです。
データメッシュを効果的に実現するには、複数のサービスを組み合わせて各ドメインに適用する必要がありますが、選択を誤ると技術的負債を負うリスクがあります。データレイクのような統合型アプローチを採用するか、あるいは分散型のデータメッシュに適したソリューションを選択するかは、慎重に判断する必要があります。
データメッシュを効率的に一元管理できるクラウドサービス
データメッシュを実現するには、「データプロダクト」の共有に対応したクラウドサービスを利用します。一例を挙げると、「Snowflake」と「Databricks」です。
「Snowflake」と「Databricks」は、データ共有、データカタログ、データウェアハウスなどの機能を統合したオールインワンサービスを提供するプラットフォームです。主要なパブリッククラウド上で稼働し、異なるクラウド環境にまたがるデータメッシュを効率的に一元管理することが可能です。
注意点としては、パブリッククラウドをまたがってデータ共有する際はデータ複製機能を有効にするなど、単一のパブリッククラウド上での利用に比べると制約や煩雑さがあります。データメッシュでは「データプロダクト」やデータガバナンスに利用するサービスを統一しておく必要性が強いです。
データメッシュは、2019年に生み出されたばかりの概念で、まだまだ成熟途上にあります。より柔軟に、効率よく構成できるよう、今後のさらなる発展が期待されます。
パブリッククラウドサービスでのデータメッシュや、データメッシュ構成時の検討ポイントについては、日経クロステック記事で説明しています。ご興味のある方はご覧いただければと思います。SnowflakeとDatabricksについては、今後詳しい記事を掲載する予定です。
次回のテーマは「データ活用のアプローチ」です。データ活用にはトップダウンとボトムアップのアプローチがあり、それぞれの特徴とメリット、デメリットについて解説します。データ活用のテーマや組織文化など、どちらのアプローチを取るべきかの検討材料になると思います。






















